FreeLLMAPI-链接各大免费大语言模型,每月可用免费17亿token
FreeLLMAPI一个兼容OpenAI的终端。将 Google、Groq、Cerebras、SambaNova、NVIDIA、Mistral、OpenRouter、GitHub Models、Cohere、Cloudflare、HuggingFace、Z.ai(Zhipu)、Ollama、Kilo、Pollinations 和 LLM7 的免费套餐汇聚,以及任何自定义兼容 OpenAI 的终端(llama.cpp、LM Studio、vLLM、本地 Ollama)——都集中在单一终端下。密钥是加密存储的。路由器会为每个请求选择最佳可用型号,当某个供应商有速率限制时切换到下一个供应商,并跟踪每个密钥使用情况,确保你能在每个免费套餐的上限内保持。
现在每个严肃的人工智能实验室都提供免费方案——每月几百万代币,每天几千个请求。单独来看,每一层都是一个玩具。它们叠加起来,每月大约有17亿个推理能力,涵盖从小型快速到合理能力的100+模型。
问题在于手动堆叠非常痛苦:十六种不同的SDK,十六种不同的速率限制,十六个请求可能失败的地方。FreeLLMAPI 将其整合到一个兼容 OpenAI 的端点中。将任何OpenAI客户端库指向你的本地服务器,它会透明地在你添加密钥的供应商之间路由。
特色
兼容OpenAI——并且可以与官方OpenAISDK及任何兼容OpenAI的客户端(如LangChain、LlamaIndex、Continue、Hermes等)协同工作。只要改变。POST /v1/chat/completionsGET /v1/modelsbase_url
响应 API ——(当前 Codex CLI 版本所需的线格式)作为同一路由器上的翻译 shim 实现,包含完整的流事件和工具调用。POST /v1/responses
流式和非流式——服务器发送事件,否则JSON响应。每个供应商适配器都实现了这两种功能。stream: true
工具调用——类似OpenAI的请求通过传递,助理+角色跟进消息在各供应商间往返传递。toolstool_choicetool_callstool
自动切换——如果所选供应商返回429、5xx或超时,路由器会跳过该程序,将密钥置于短暂冷却时间,并在备用链中的下一个型号上重试(最多20次尝试)。
按键速率跟踪——每个键有RPM、RPD、TPM和TPD计数器,所以路由器总是选择位于其上限下的键。(platform, model, key)
粘性会话——多回合对话会与同一模型对话30分钟,以避免因对话中途切换模型而产生的幻觉激增。
加密密钥存储——API密钥在进入SQLite前用AES-256-GCM加密;解密发生在请求前的内存中。
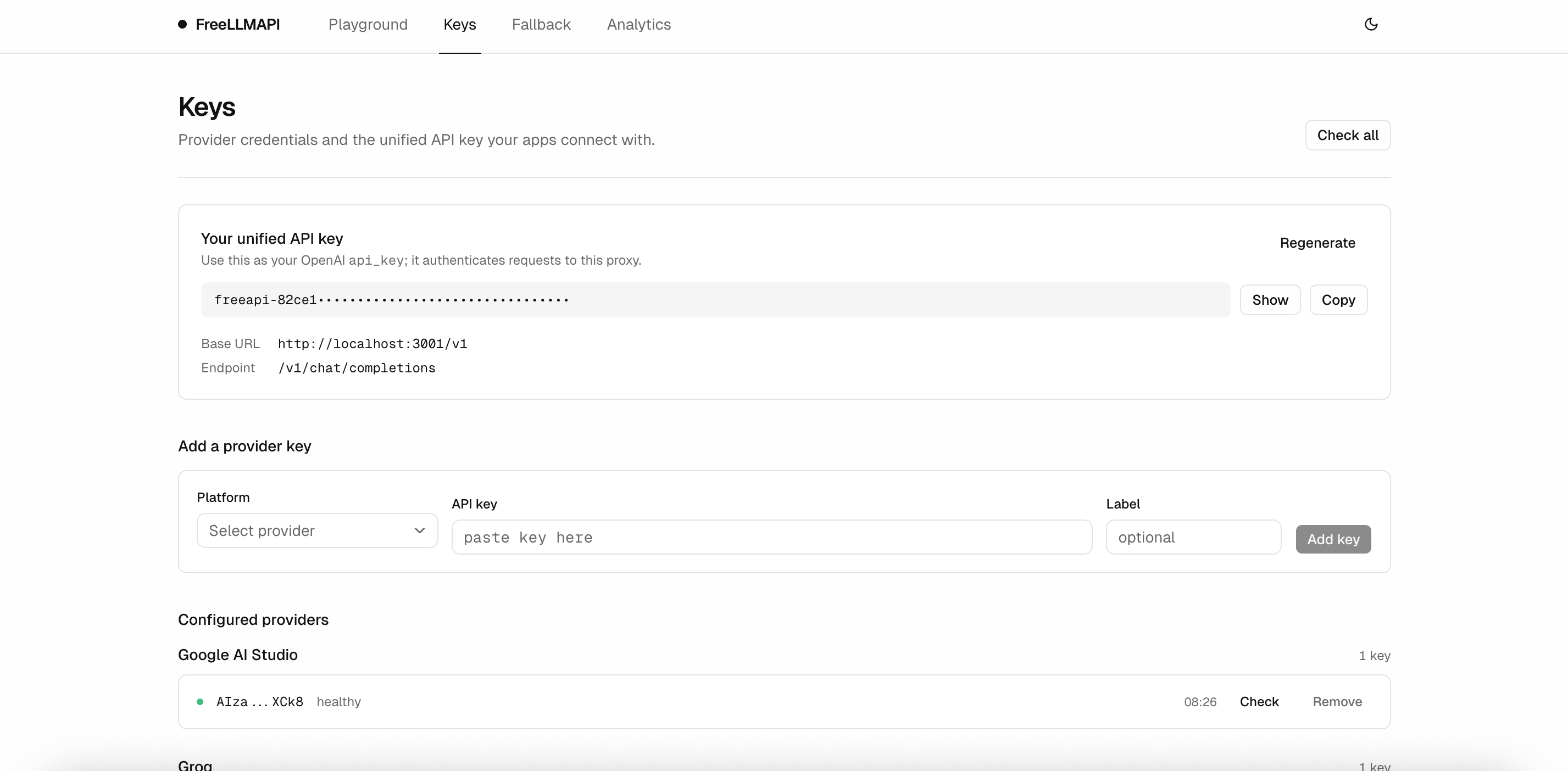
统一API密钥——客户端用单一持有令牌向你的代理进行认证。你绝不会向你的应用暴露上游的提供商密钥。freellmapi-…
仪表盘登录——管理界面和所有路由都被封锁在一个电子邮件+密码账户(加密哈希,会话令牌认证)后,首次运行时设置。代理为应用保留统一密钥认证。/api/*/v1
健康检查——定期探测会将键标记为 、 、 ,或者路由器会自动跳过失效键。healthyrate_limitedinvaliderror
管理仪表盘 — React + Vite UI,用于管理键、重排备用链、检查分析并在游乐场中运行提示。包括暗黑模式。
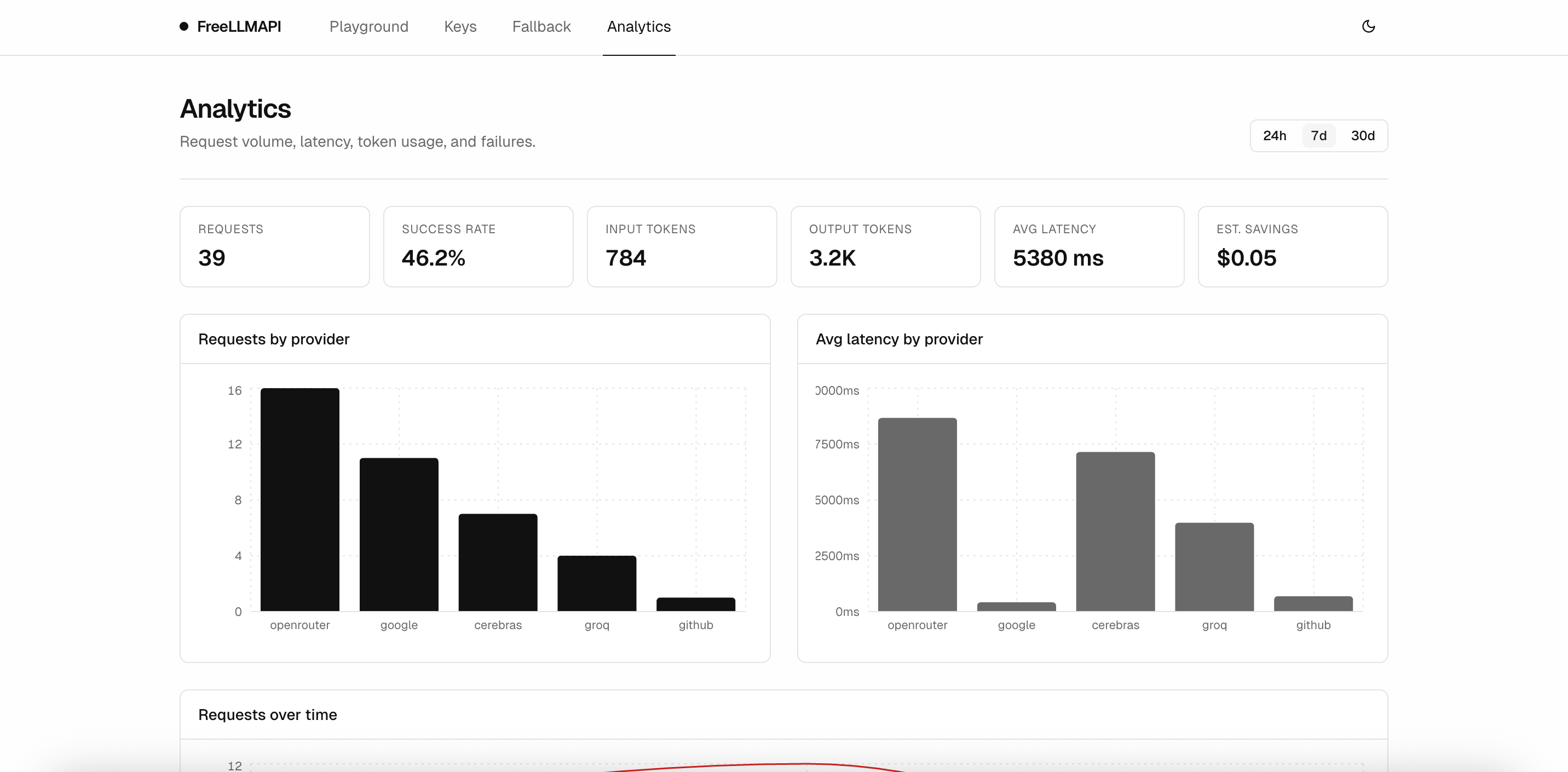
分析——按请求记录,包含延迟、令牌数量、成功率和各供应商的分析。
运行在Node 20+运行的任何地方——Windows、macOS、Linux服务器,或小型ARM SBC(包括树莓派)。~40 MB RSS,空闲时在 PM2/systemd 或你喜欢的 supervisor 后面。
截图